Debugging Python or Deadlocks in Graphite
I found a StackOverflow post that helped save my day. I’ve been dealing
with a bug in Graphite’s carbon-cache.py daemon (version 0.9.12). It hit
me badly during a cluster expansion and I know I have hit it before. I
had to find it.
This StackOverflow post gave me the magic I needed to signal the process to dump out a Python traceback of all running threads. That was the catch, dumping all threads.
import threading, sys, traceback
def dumpstacks(signal, frame):
id2name = dict([(th.ident, th.name) for th in threading.enumerate()])
code = []
for threadId, stack in sys._current_frames().items():
code.append("\n# Thread: %s(%d)" % (id2name.get(threadId,""), threadId))
for filename, lineno, name, line in traceback.extract_stack(stack):
code.append('File: "%s", line %d, in %s' % (filename, lineno, name))
if line:
code.append(" %s" % (line.strip()))
print "\n".join(code)
import signal
signal.signal(signal.SIGQUIT, dumpstacks)I changed the print statement to output to Graphite’s log files.
What I knew and what I had:
- My bug happened after the writer thread hit a unexpected exception
in the
whisper.update_many()function. - I had figured it crashed or somehow hung up the entire writer thread
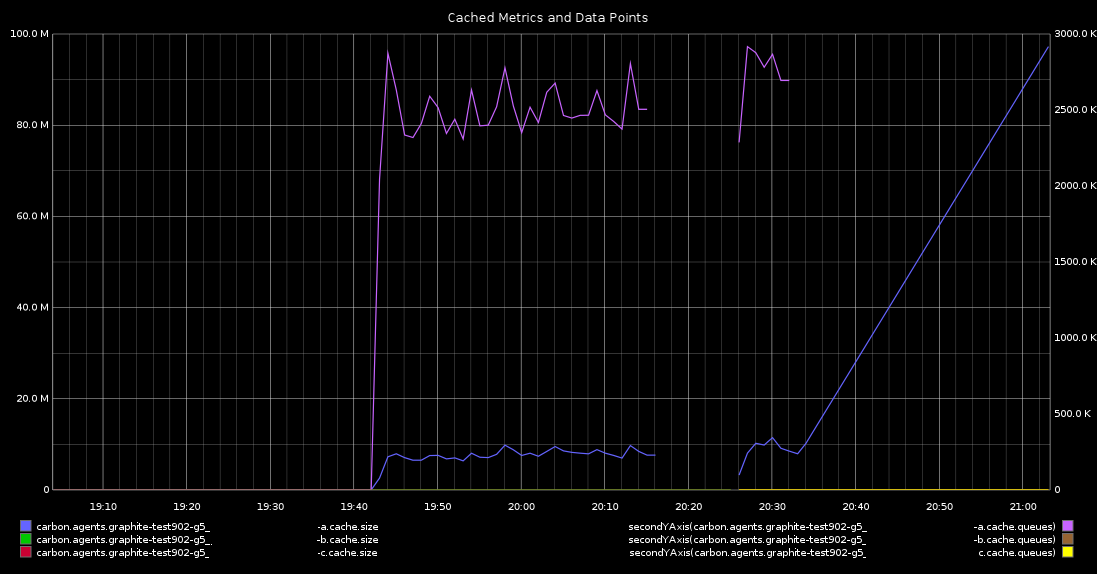
- The number of data points in the cache sky rocketed when the bug manifested and all writes to WSP files stopped.
- Tracing through the code I knew that unexpected exceptions in
whisper.file_update_many()bubbled up pastwhisper.update_many()which skipped closing of that file. - I saw via
lsofthat the process would hold open the bad Whisper file. - This happened under pretty heavy load. About 250,000 metrics per minute.
- I had a really bad load tester.
- I had beefy test machines.
It took a while bug I figured out how to reproduce the conditions and hit
the bug. I had some extra logging in writer.py to help figure out what
was going on. But I knew I needed a stack trace of that particular
thread when this happened to nail down exactly what was really going on.
So, I reset my test and added the above code to writer.py. A few minutes
later I had triggered the bug again.
# kill -sigquit 3460
Suddenly, I had a traceback in carbon-cache-a/console.log.
# Thread: PoolThread-twisted.internet.reactor-1(140363856660224)
File: "/usr/lib/python2.7/threading.py", line 524, in __bootstrap
self.__bootstrap_inner()
File: "/usr/lib/python2.7/threading.py", line 551, in __bootstrap_inner
self.run()
File: "/usr/lib/python2.7/threading.py", line 504, in run
self.__target(*self.__args, **self.__kwargs)
File: "/usr/local/lib/python2.7/dist-packages/twisted/python/threadpool.py", line 191, in _worker
result = context.call(ctx, function, *args, **kwargs)
File: "/usr/local/lib/python2.7/dist-packages/twisted/python/context.py", line 118, in callWithContext
return self.currentContext().callWithContext(ctx, func, *args, **kw)
File: "/usr/local/lib/python2.7/dist-packages/twisted/python/context.py", line 81, in callWithContext
return func(*args,**kw)
File: "/opt/graphite/lib/carbon/writer.py", line 168, in writeForever
writeCachedDataPoints()
File: "/opt/graphite/lib/carbon/writer.py", line 145, in writeCachedDataPoints
whisper.update_many(dbFilePath, datapoints)
File: "/opt/graphite/lib/whisper.py", line 577, in update_many
return file_update_many(fh, points)
File: "/opt/graphite/lib/whisper.py", line 582, in file_update_many
fcntl.flock( fh.fileno(), fcntl.LOCK_EX )
Also, a graph to further show that I had hit the bug I was looking for.
Finally, I knew what was happening:
- I have locking enabled for safety.
- On error, the Whisper file wasn’t closed
- The Python GC never got around to closing the file – which means it was never unlocked.
- The metric came around in the cache again to update.
- Boom! The writer thread was deadlocked.
The moral of the story: Always close your files.